Scaling Language Models with LLMOps in Real-World Applications

Introduction
Large language models (LLMs) have emerged as a driving catalyst in natural language processing and comprehension evolution. LLM use cases range from chatbots and virtual assistants to content generation and translation services. As the need for more powerful language models grows, so does the need for effective scaling techniques.
This article explores the concept of large language models, their importance, and their crucial role in real-world applications.
I didn’t make any of these up. What if I told you that language models have revolutionized how we interact with technology, and you can be part of this great revolution?
What are Large Language Models?
Large language models are foundational, based on deep learning and artificial intelligence (AI), and are usually trained on massive datasets that create the foundation of their knowledge and abilities.
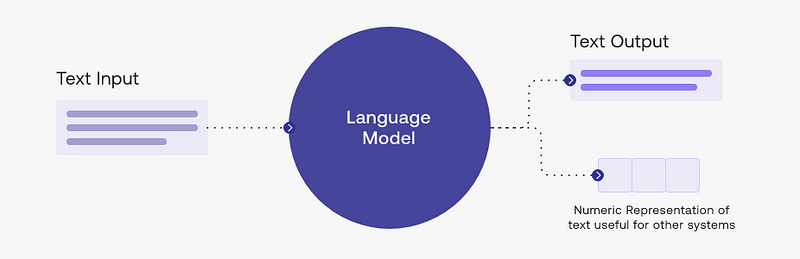
As shown in the image above, LLMs take texts as input. The language model has been trained on large text datasets and predicts the words in sequence. For example, whenever you input a new piece of text to process, it uses this knowledge to anticipate the subsequent word in sequence.
Large Language Model Operations, also known as LLM Operations or LLMOps, refers to the collection of tools and procedures used to effectively optimize, manage efficiently, and scale language models for practical applications.
LLMOps is a set of techniques and best practices designed to deploy LLM-powered solutions at scale, guaranteeing peak performance and security. These procedures are instances of the foundation model applied to activities such as training (large datasets), deployment, testing, and monitoring. Each of these factors is essential to the lifetime management of the language models.
LLMOps deals with the entire lifecycle of LLMs, from data management to model development, deployment, and ethics. It involves establishing a standard workflow for training LLMs, fine-tuning (hyper) parameters, deploying them, and collecting and analyzing data (aka response monitoring). Like machine learning operations, LLMOps involves efforts from several contributors, like prompt engineers, data scientists, DevOps engineers, business analysts, and IT operations. This is, in fact, a baseline, and the actual LLMOps workflow usually involves more stakeholders like prompt engineers, researchers, etc. Although LLMOps apply MLOps principles, it greatly emphasizes performance, reliability, and scalability.
Next, we’ll look at how companies are using LLMOps to improve the performance of their LLMs.
Case Studies: How Companies Are Using LLMOps
Large language models can be applied to a wide range of real-world scenarios. First, you need to understand specific instances or situations where these practices and tools can be used to achieve your goals. Then, you can move forward to incorporating them into your business.
Large language models are driving innovation across the tech world. For example, companies like Meta leverage LLMOps to design and deploy their models, such as Code Llama, which powers various product features. Similarly, Google utilizes LLMOps for its next-generation LLM, PaLM 2. PaLM 2 excels at complex tasks like code generation, question answering, and natural language processing, making it valuable for various applications.
Practical Applications of LLMOps in Real-world Scenarios
- Marketing: You can tailor your marketing campaigns to each customer’s needs by deploying LLMs. This can help drive more sales and better serve your customers. However, you must be careful to avoid data privacy scandals by gaining their consent.
- Content Generation: Large language models (LLMs), powered by natural language processing (NLP), can assist you in creating informative material such as blog articles, website content, social media posts, and infographics. LLMs simplify the content development process by allowing you to concentrate on other tasks while they handle the initial generation.
- Chatbots: Your customer support team can leverage the power of LLMs to supercharge chatbots and virtual assistants. They can answer any questions users may have. You would simply provide documentation, policies, and FAQs.
- Instant Translation and Localization: LLMs can help your localization team serve your users’ content on the fly and in their preferred languages. The quality of text translation is considerably improved with LLMs compared to rule-based techniques.
- Web Scraping: LLMs can be trained to gather information from the internet at lightning-fast speeds. These models can crawl a website and ingest its information to unlock a whole new level of interaction—not unlike communicating directly with the website!
LLMs like Falcon 40B and GPT-3 are well-equipped to handle various tasks, from text classification to sentiment analysis and content generation.
How does LLMOps make LLMs practicable and scalable?
- Successful Training: Efficient training requires improving the training process to produce the best outcomes while minimizing resource consumption, training time, and any superfluous expenses.
For example, parallel processing is used to speed up the training of these models. - Customization for Specific Tasks: Customizing for a specific task is inevitable when working with large language models. This entails adopting a pre-trained language model and customizing it to execute a more specialized task or collection of activities.
- Deployment Optimization: LLMOps uses API integrations for seamless interaction with real-time applications and implements advanced load-balancing algorithms for optimal efficiency and performance. These algorithms ensure that incoming requests are spread fairly among numerous model instances, reducing server overload.
- Scalability: Scalability is a core part of LLMOps, as it allows large language models to adapt and expand as demand grows, efficiently manages model versions and smooth updates, and guarantees that newer, improved models can be deployed without disrupting ongoing services.
Let’s look at four tips for scaling LLM workflows with LLMOps.
Scaling LLMs with LLMOps: Techniques and Best Practices You Should Know
In building LLM-powered applications, here are some key points you should note to guarantee optimal performance in your LLMOps processes.
Decide Which LLM to Choose
Many large language models exist as active research continues in the ML space. Popular LLMs include Falcon 40B, GPT-4, LLaMa 2, and BERT. These LLMs perform natural language processing (NLP) tasks and are used in various relevant fields of application.
Choosing the right one(s) is essential to achieving a streamlined end-to-end LLMOps workflow. However, selecting an LLM that best fits your project is no walk in the park. Several factors to consider include model output quality, response speed, level of data integrity, and resource and cost constraints.
Most experts consider GPT-4 a great entry point for businesses leveraging AI for their processes. It offers high-quality output and seamless deployment of LLM-powered applications; however, it is proprietary (more on this later), and you might quickly rack up high usage costs as you add more users.
Ultimately, it’s best to analyze your application’s needs and specs first. Let’s say you need a cheaper option for deploying simple solutions. Then, you might consider models like LLaMa—or even GPT-3.
Prompt Engineering
Prompt engineering is a critical component of LLMs. These models have been trained on diverse datasets and usually have general applications. As such, they might not be as specialized in handling specific tasks your application requires. This is the stage at which prompt engineering is crucial.
Prompt engineering allows you to customize your input prompts to produce specific outputs. This process involves exploration (and perturbation), testing, iteration, and monitoring.
During exploration, you clearly define the LLM’s task and what you aim to achieve. Prompt testing involves generating initial prompts, feeding them into the model, and analyzing the outputs.
Iteration is based on feedback, which is used to fine-tune the prompt and validate the changes. Finally, monitoring is a continuous process of maintaining the prompt’s performance over time. Prompt analytics tools can also help visualize prompt performance—the prompt must adapt to user feedback and evolving requirements.
“Open Source or Not?”
There are currently two categories of LLMs based on ownership: open source and proprietary. Companies own proprietary LLMs, which cannot be used without a license, which usually restricts the usage of the LLM.
Open-source LLMs have made their source code and design accessible to anyone. This means developers, researchers, and enthusiasts can freely use, modify, and distribute the code, promoting innovation, collaboration, and community development efforts.
Proprietary LLMs offer high-quality outputs since they’ve been trained extensively on diverse datasets. They are often used as a benchmark for other models since they perform considerably better. However, usage costs are a real pain, and proprietary LLMs are no exception.
Conversely, open-source LLMs are more transparent and flexible since your in-house AI team can easily customize the specs and visualize the algorithms. This promotes compliance and improved performance.
Open-source LLMs also save costs since no licenses are involved. Several free-to-use LLMs have various general-purpose, domain-specific, multilingual, and task-specific applications.
Test. Deploy. Monitor. Repeat.
LLM deployment in production environments is critical for ensuring optimal performance and scaling to meet your application’s requirements.
Here’s what you should know:
Deployment deals with creating the infrastructure needed to run the model, setting up an API to integrate the model with your application, and ensuring the model runs efficiently. One of the best practices for LLM deployment is test-driven deployment (TDD).
Since LLMs need constant attention and adjustment, testing models between deployment iteration is important. TDD is a four-step approach that allows you to implement tests before writing a line of code.
First, you create a test by defining the expected behavior of the LLM in a specific test case. Then, you run the test. Of course, the initial test will most likely fail since the model hasn’t been trained to pass the case. So, you have to tweak the model with the test case in mind (fine-tune parameters and prompts or adjust the additional processing of the model response) and repeat the process.
Monitoring involves tracking the model’s performance based on key metrics, such as accuracy, latency, calibration, toxicity, zero-shot evaluation, resource usage, fairness, and bias. Response analysis also helps to identify errors and inappropriate responses. Monitoring helps tweak parameters and fix errors to improve model output quality.
Wrapping Up
LLMOps is a set of practices for managing, optimizing, and scaling large language models. Throughout this article, you have learned the importance of selecting the right large language model, the difference between an open source and proprietary model, the role of prompt engineering in customization, and best practices for implementing and monitoring LLMs. I also iterate how LLMOps have the potential to transform language model applications and provide direction for interested people exploiting these models for specific projects.
Related Articles

